
- Popular Post

Charon117
-
Posts
325 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Calendar
Posts posted by Charon117
-
-
@dimitrius154 Nice. You dont mention this in the OP, it might be good to.
-
@Flix Thats all I can think of right now. If nothing else comes up EE 2.3 should be compatible with the modmerge system out of the box. And the --//Overwrite really is only usefull if you changed something else than questcreature, questitem and createquest.
-
@Flix In preparation for the modmerge system can you add
--//OVERWRITE
to the head of the quest.txt ? You will find an example in the Sacred 2 Modmerge Example folder.
-
Quote
- Prepared some script formatting in anticipation of compatibility with mod merge project.
I have tears in my eyes
") .
.
@gogoblender Technical aspect: the subforum doesnt show that the thread has a new message to me. Slow Update process ?
-
2 hours ago, Flix said:
Just curious, why change 2 to 5 and not 1? I guess it probably won't matter if 1 is skipped, just seems strange to make all of these range 2-5 and not 1-4.
There is no reason to it. Just conformity.
If you think logical than you would realise that 1 - 3 are standard spawns. From the information I gathered the "Weihnachtsbaeume" are bonus content, put in by CP folks after the fact. They have ids 2 and 3 either because the original developers didnt care to give them proper ids because it was a time limited content, or becauset the original entries of 2 - 3 got removed during that time, The latter is what I suspect. Either way, the non Weihnachtsbaeume 2 - 3 ids are obviously the original content, and the Weihnachtsbaeume are bonus content, which means its logical to continue counting after ids 1 -3. Having bonus content start after the standard 1 - 3 identification is more coherent than to split up bonus content to 1 and 4. I also suspect 1 to have existed in the past, but removed or merged, which makes the reentry of non bonus content for id 1 more likely than bonus content requiring id 6.
-
I grabbed a clean CP 1.6 build, then applied the following mods
- Elite Textures
- EE 2.2 Enhanced Spells
- EE Superspawn (fixed the issue with triple to dual identifier)
- EE Challenge
- Flix music
- Disable Splash
- Readable Console
- Boss Farms (quest.txt)
- Mob Farms (quest.txt)
- Diverse movement speed
After each step I started up the game at least once, checked the game for obvious bugs, teleported once, and ran around a bit. At no step did any crash or corruption occur. Logfile is intact, equipment obviously changed a bit from the CP > EE item ids. I cant seem to find a major issue with the modmerge installer.
-
I see an "Extra" folder in your game. Care to explain what it is about ?
-
Tested spawn.txt with different layermap_id s and the game seems to behave normally up to a tested layermap_id = 6. So I assume layermap_id is what it says it is, a simple id.
I ask all major modders to change their spawn.txt according to the table below.
I would like to get the source of this problem fixed too - the CP, but as somebody else said, thats unlikely to happen.
mgr.addSpawn (61,13,0,{ -- Wald 4 ||| layermap_id = 3, - change to layermap_id = 4
mgr.addSpawn (11,51,0,{ -- Harpien Dunkle Rituale ||| layermap_id = 1, - change to layermap_id = 4
mgr.addSpawn (58,54,0,{ -- Weihnachtsbaeume ||| layermap_id = 3, - change to layermap_id = 4
mgr.addSpawn (58,54,0,{ -- Weihnachtsbaeume ||| layermap_id = 2, - change to layermap_id = 5
mgr.addSpawn (58,55,0,{ -- Weihnachtsbaeume ||| layermap_id = 3, - change to layermap_id = 4
mgr.addSpawn (58,55,0,{ -- Weihnachtsbaeume ||| layermap_id = 2, - change to layermap_id = 5
mgr.addSpawn (58,56,0,{ -- Weihnachtsbaeume ||| layermap_id = 3, - change to layermap_id = 4
mgr.addSpawn (58,56,0,{ -- Weihnachtsbaeume ||| layermap_id = 2, - change to layermap_id = 5
mgr.addSpawn (59,55,0,{ -- Weihnachtsbaeume ||| layermap_id = 3, - change to layermap_id = 4
mgr.addSpawn (59,55,0,{ -- Weihnachtsbaeume ||| layermap_id = 2, - change to layermap_id = 5
mgr.addSpawn (59,56,0,{ -- Weihnachtsbaeume ||| layermap_id = 3, - change to layermap_id = 4
mgr.addSpawn (59,56,0,{ -- Weihnachtsbaeume ||| layermap_id = 2, - change to layermap_id = 5With this the spawn.txt identifier will get reduced to sector position + layermap_id, which will allow mods to change density of existing entries, like Flixs SuperSpawn mod does for instance. Older data will still have that problem but at least the gateway of bigger mods will have it fixed.
Thank you for your time.
-
So, guys. My main question is, when can I release the software ? Since I dont have any testers, Flix isnt in town, dimitrius is busy with addendum, I can "never" release it, since it will never see any testing.
So my question here is, who is willing to test the software throughly in a timely manner, or know people who are so happy about something like this existing that they would spend time on testing it ?
@Flix @dimitrius154 @Androdion @gogoblender
If we dont find any testers the Modmerge Software will simply go out marked as BETA and untested.
-
On 1/27/2020 at 5:37 PM, Flix said:
I believe it can go in pak/data/outgame
The original is packed in a zip file, I believe it's pak/skin.zip
I'm not at home nor do I have an install that I can check at the moment, sorry.
Come home quickly :). and safely.
Edit: Refreshed Link: [Deleted] Download again please.
Edit2: Do you like the installer framework, or should we just cut down everything to a pure console build ?
-
@Refresh the post above. This can be deleted after the notice.
-
@Flix Quick question, where is the main menu image stored ?
This is the rough prototype: [Deleted]
The "Sacred 2 Gold Modmerge" folder is the folder in which you put your modding content, just like usual, as you would into your main Sacred installation folder.
- Start "Sacred 2 Modmerge Installer.exe" ( the name will be incorrect due to forum autocorrect bot, slap ) and insert your installation folder, and whether you automatically want to remove animation dublicates. It creates a folder called InstallSettings.txt
- The installer will call Sacred2cpp.exe with InstallSettings.txt on its list to load. It will produce a logfile called logfile.txt and automatically finish
- done.
Source Code is included. And the Sacred 2 Gold Modmerge examples folder gives a file by file explanation of what data the modmerge system takes.
@Flix @dimitrius154 @Androdion @gogoblender
You have to let the installation run at least once, but afterwards you can quickstart it with the last settings by starting Sacred2cpp.exe directly.
I need feedback whether or not that is exactly what you need, and in what direction the product should improve in. And ofcourse whether the installation works as expected.
-
This is a letter I sent one of my colleagues about nomenclatur. (C++)
QuoteWe need to talk. Whenever you are ready.
So following your suggestions about nomenclatur, and your critic about not knowing the intention of a variable I want to formulate the following thesis after my experience.
Your initial critic that lFileA is not something you understand, apart from that I hope that it contains a file, I redeclared it as mergeFileList. I felt it was necessary to add the "List" so that I, as a programmer, know what I am dealing with. Otherwise I would have to ask myself, is it a file as a string, a vector, a list, an array ... ?
Now this name already has a ton of problems in it, but I will point them out as we go.The next thing to rename would be itLAUppDelim, which is an abbreviation for "iterator List A Upper Delim". An abbreviation which I felt contained all the necessary information you need as the writer as well as the reader of a program as well as being short, and distinctive. But that was obviously not ok for several reasons. First, type inclusion ages VERY badly. Enough literature has been written on why type inclusion into naming is bad, and makes code maintenance a nightmare, so I wont go into that. Secondly "List A" is an identifier which obviously revers back to lFileA, but that is not knowable without the context.
This pretext leads us up to the question: "What is a good nomenclatur in programming ?".
The first we have to ask is what is "good" ?
The best definition that I can currently come up with is
good = that, which drives you closer towards your (practical) goal
bad = that, which drives you away from your (practical) goalThis definition creates the logical question of what your practical goal is that you are trying to reach. Code doesnt have to be the best code if you go back a thousand years, and it doesnt necessarily have to be the best code in a thousand years, aka 3020. What "good" and what "bad" is always changes depending on your goals, and your goals also keep changing all the time, which makes "the" best nomenclatur an unreachable stage. A good nomenclatur always changes depending on the goals and the environment.
The next logical conclusion is to ask what the (pragmatic) goals are that we currently try to reach.First of all the nomenclatur needs to make me want to work with the program I am currently writing at. While programming conventions over the spawn of 10 years can change, it doesnt change the fact that now I am working with a limited amount of knowledge, with limited skills and with a tool that cant do everything, but is also very much limited in what it can do. While I dont want to delude programmers who read the program in 10 years with a nomenclatur that doesnt make sense to them then, I would like to know where I am with my current skill level, my current knowledge and working with the current tool which altogether limits of what I can do in a very real sense.
Readability. What is a "readability" ? Readability is the easiness of which meaning manifests itself to the reader. What is a "reader" ? A reader is somebody who does not have any pretext of what code is trying to achieve. This can be a random person, your coworker, or yourself after reading the code you wrote 5 months, 2 weeks or 5 days ago.
The best readability is if a reader can read a random line of code, and deduct of what it is trying to do without knowing any context.
The worst readbility for a programme is if the reader has to read the entire code in order to understand what a single line does.
And then ofcourse there are infinite variations inbetween.
As you can see there are not infinite goals, but only 2 very concrete people we have to satisfy, the Writer and the Reader. Too many people insist on styles which do not satisfy both ends, but enough people talk about their style as "the best of both worlds", which might be true for them, but is hardly transferable to other people who might have different cultures and context knowledge.
Taking this knowledge into account lets take a look at itLAUppDelim and lFileA. The cure for lFileA seems to be mergeFileList. First it eliminates the data type, and secondly it describes what it is, AKA it is the merging File.
what is itLAUppDelim ? iterator List A Upper Delimeter. Thats obviously not good so how about mergeUppDelimIterator ? [merge] describes that it belongs to mergeFileList, [UppDelimIterator] describes in a very real sense of what it is, namely an upper delimeter iterator.The first problem I have with this is that while we remove the data type from the name, we kinda sneak it back in with [Iterator] and [--List], a requirement for the Writer to orient himself. The second problem is that while mergeFileList makes it easy to deduct that it means the merging file, mergeUppDelimIterator is kinda ambigious. Are we trying to merge the Upper Delimeter with something else ? Who knows ? BUT WAIT you are going to say, we only added the [merge] because it belongs to mergeFileList. [merge] is not an action, adjective or noun, it is an identifier. This identifier tries to logically link together two variables, functions, Macros, classes or templates, implying that they have some kind of connection, which sets them apart from other code. OK, valid point.
This is why I want to to introduce Identifier into the nomenclatur. Identifier are a means for orientation for the Writer and Reader alike. Once the Reader and Writer know what a variable, function, macro, class and template is trying to achieve an Identifier tries to give an approximate orientation of where that function, ... belongs to, and has its place in the code.
An example for that would be a23File. Nobody needs to know what [a23] means, all you know is that that variable is a file in some form, and that it is connected with other stuff which are also tagged as [a23]. Identifier address a lot of pragmatic problems that crop up during development, for instance if you use vectors and lists you will necessarily have a lot of iterators. Most of them will be named very similarly, and if you process data deeply most of them will named even more alike. Trying to pull identifiers from the meaning of other variables quickly leads to confusion, especially for prolonged development. It leads to confusion because the Writer and Reader read it as something meaningfull, while it only tries to show a connection between functions, ... etc.
Skipping a lot of the practical problems and going straight to the point
Because of the points mentioned above
I suggest the following system.
[Identifier][Meaning]_[Orientation for the Writer]
[Identifier]: The Identifier consists of only lowercase letters or numbers, and is supposed to be held like a deep directory. For instace mFile is a file which belongs to the identifier m, and miManager is a process which belongs to m and I, in that order. mimClock is a function, ... which belongs to m, then I, and then m again. If you are reading mimProcess than you obviously know that there are 3 additional layers where something interesting might go on. Only single letters or digits for each "directory" level. m =/ mi=/ mim.
The Identifier compresses a lot of context information, which is not necessary for the Reader to understand a random line of code, while showing the connection to the Reader and Writer as soon as more context is aquired.
It is important to note that that the Identifier doesnt have to be dead accurate in hindsight. It is not meant as a replacement for checking the code, but as a guideline for which code to check first. The Identifier does not replace context knowledge, it just is an arrow into which direction context knowledge is most likely to be found first.[Meaning]: Simply put, this is what you are trying to achieve in its purest form, without being burdened by having to hint at connections to other functions, ... or by having to orient yourself by adding [--List] and the like. Write it like you are shakespear. Write it like you want to read in 5 days, 2 weeks, and 5 months. Verbosity is encouraged, Keep it as short as possible, but dont compromise on the meaning. Be Wild, Be Yourself. Also [Meaning] uses Camel Case, so as soon as you get to the first capital letter you know you arrived at the [Meaning] of the function, ... .
[Orientation for the Writer]: Dividing the common orientation and the meaning from the exclusive orientation for the Writer with an underscore is this. Every person is in a unique constellation of a personal skill level, knowledge, coworkers, environment, IDE, language limitations, and infinite other influences, too many to count them all, which limits the scope of the Writer in a very meaningful way of what is currently important. Write in lowercase single letter and digit abbreviations what is important for you, the Writer. If you currently need to keep in your head whether you are dealing with 16bit encoding or 32bit encodinging than write mimFile_32b. Is it important for you to know the data type than write mimFile_ls. Or maybe mFile_liststring. Do you need to single out any important information which is necessary to know for you currently, write it down I a short lowercase abbreviation you, and only you, have to understand.
Functions, ... dont have to have this, the [WriterOrientation] can also be completely missing.Applying above rules to the examples given above we get this.
From our original lFileA, over mergeFileList we would formulate it as mMergeFile_ls.
itLAUppDelim > mergeUppDelimIterator would consequently become mUpperDelim_lsit.
I find this naming convention to be more appropriate and a lot better to read, as the Reader can start to read the [Meaning] immediately with the first capital letter, while [WriterOrientation] doesnt have to be correct, meaningful or even looked at by anybody, but the Writer of the code. The Identifier provides additional context direction for both the Writer and the Reader alike, while not claiming to be correct at any given point. Also the main() function has an empty Identifier eg. File_lsit.
With this we satisfy both the Reader and Writer alike, as a Reader doesnt need to look at information he/she would need more context to understand, while the Writer can orient himself while always knowing that neither the [Identifier] nor the [WriterOrientation] are a substitute for checking the code.
Another point. Some people are stuck in naming paralyses, which means they spend time not knowing what their function, ... will do, and therefore cant come up with a fitting name for it. That is completely natural, and can be avoided 100% by simply not naming functions, ... before you write the code. Put in a placeholder name which approximitelly describes what it should do, write the code, then update the name accordingly. In the best case you put a placeholder name down, write code until you go out of scope, then read what your code does, and then find the most fitting name for it. Most IDEs should have no problem with replacing context specific, but even with standard text editors this shouldnt be a problem. Worst case scenario you can make custom delimeters like xxx_IDontKnowWhatThisDoes_xxx.
These rules are not set in stone, subject to change and are meant to be used in conjunction and addition to any existing ruleset there. I would like to know what you think about this and hope my message finds you in your best health,
[Charon][overly official :p]
-
23 minutes ago, Androdion said:
If that's per line changed then I can see the issue, if it's per package of changes I don't think it's that bad.
Its per mod. And not even that necessary, as people could just link to the common download source. But thats not the issue, the issue is in how-does-the-user-interact with the software.
1. If somebody wants to install a mod and the software is included in the package its most convenient. Convenience at the cost of 10mb.
2. If mod authors link to the source, and people would have to put both pieces together it makes it more traffic friendly, but less convenient, because users would have to switch out the modding content everytime.
-
The modmerge software is meant to execute data changes in the already given form. For instance you could write
AdjustCriticalDamageFactor = 1700,
to adjust the criticial hit factor of your current build. A single line like that takes 36 bytes to save, while if you want to execute it, you would need to add a 10 mb software.
I think its better to start off with the 2 main purposes of the software.
1. The modmerge software generally enables to save mods as a set of instructions, instead of complete files. The advantage of this is by taking the example above that if you simply want to publish a mod that changes the critical hit factor you can do so, without people getting their 97 other code lines in balance.txt altered.
An existing example would be Flixs EE Challenge mod, which is basically just 6 altered lines in balance.txt. Due to the current nature of how mods are distributed he has to publish the whole file. It works fine for somebody who plays EE anyway, but somebody else who doesnt necessarily play EE will also get all other 90 code changes in balance.txt which are synced with EE, and not necessarily to any other build.The modmerge system would mean that Flix could publish a Challenge mod which is not only compatible with EE, but all versions and builds out there, as a six-liner.
Any kind of mod could be applied to any kind of currently existing build. If you want to make a sword, give it attributes, and set who drops it you can do that and publish it in a form that any build can take the data, reorganise it, and make it into a playable version. Instead of having a thousand splittered mods for Sacred 2 you will have ideas, which are applicable to all Sacred 2 builds. Instead of 10 authors of having to change the critical hit rate for their own mod, you can have 1 instruction file which says "Change Critical Hit rate to X".
So the first purpose of the modmerge software is to make mods (1) applicable to all builds (2) not alter uneccessary data. The main effect of this will be that (1) only ideas of mods will have to be formulated (2) you will no longer have to manually change data to avoid unecessary changes (3) mod content won´t have to be dublicated for each and every version there is.
2. Secondly, an automatic modbuilder is the goal-down-the-road. Going from the idea that the modmerge system supports single mod installs, an automated system that sequentially rebuilds your build is the goal.
Here is my example:
1. If I would want to rebuild my current build I would need to make a fresh installation, or verify game integrity via steam.
2. Then I would need to apply CP
3. Then I would need to install the Trimmed Textures
4. Then I would need to install EE2.2
5. Then E2.2 SuperSpawn
6. Then the Challenge mod
7. Then collect all the parts of Flixs music mod
8. Then install ESP
9. And then I need to manually go into every file, and change the Hireling behaviour, the balance.txt, the strenght of RpH and LL%, etc etc ... .As you can see you can take a whole evening just getting your setup straight. The modlauncher will do ALL of that for you. It will merge the data step by step as specified, and after 5 minutes running in your background you will have a working build.
The best part of this is that if you want to add another mod in the middle, you can just verify a clean installation, and run the modlauncher again.
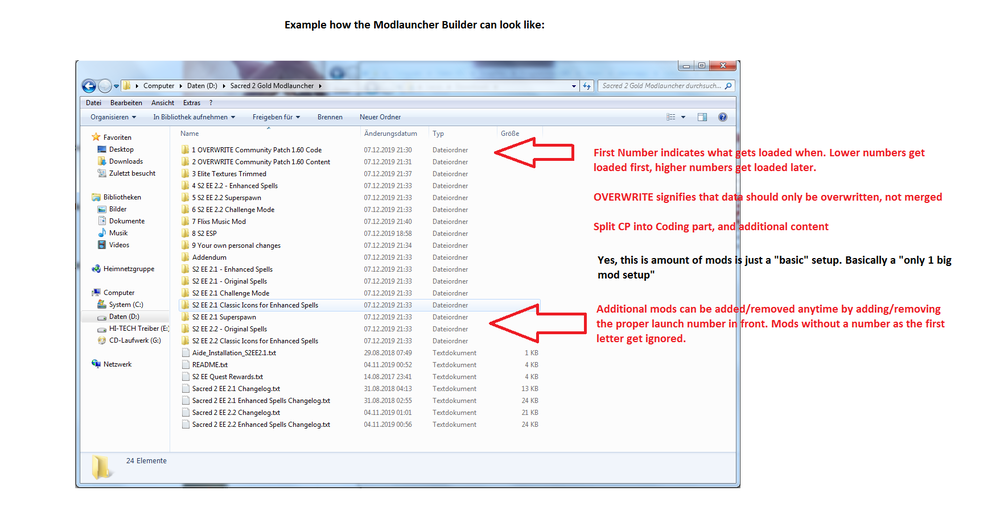
And if you want to apply a mod that you find later, you can either integrate it into your modlauncher and run it again, or apply it ontop of your current build.
The goal of this project was to get the single mod support going first, but since the size of the software would make every mod a minimum size of 10mb, and would skyrocket traffic, it wouldnt be a neat solution.
Disregarding the current situation I would like to get an idea of how the best integration of a build builder in players and modders life would look like, and what kind of features would be requested. -
Sooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo ...
I originally planned to create the software so you can add it to every mod, but now I see that the QT Core library is about 6mb, and the core c++ is around 1,3mb. In total we are looking at a 10mb software. Doesnt make a lot of sense having to append 10mb to a 2kb download everytime.
So I would like you to tell me how you would like to use a Merging Software most conveniently, and what you would like to see featured.
@Flix @dimitrius154 @gogoblender @Androdion and everybody else on this forum.
Ontopic I still need to know how to merge relations.txt and soundlcuster.txt. The problem is that it has dublicates, and since it doesnt crash one entry is obvioulsy taken over the other. In order to know if I take the first or last dublicated entry I would need to know which one is getting taken, which is why I ask somebody with a better to setup to test such than mine.
-
- Popular Post
- Popular Post
8 hours ago, Flix said:That's ok, I took a look at the golem's Energy Shield buff itself and found some parameters to adjust.
Ok, then here is the video nobody asked for :D.
-
 2
2
-
21 minutes ago, Flix said:
The trump card could be the modifier Absorption Warding Energy: Opponent -X%. In D2F I made this modifier capable of cutting through an energy shield in 1-2 hits. I can't recall if I did the same in EE. Will look into it.
Hm, I also had problems with the shield in vanilla. Dont know if that is related. The developers also hinted at an alternative way to disable the golem shield in conjunction with the stone it is throwing, but I never figured out how.
For the latest EE,SS.C run I prepared an AWEO - 33% for the char, but it didnt make any difference.
Would a video help you ?
-
26 minutes ago, Flix said:
Enough reports have come in about Gahanka and Gar'Colossus soaking up way too much damage so their vitality and physical resistance is decreased.
About the GarColossus, I believe its primarily the shield which is able to soak up too much damage. Without dedicated bypassing attacks I do zero damage on the first difficulty. Also without having access to arcane reliqs his ranged attacks are devastating.
I also believe the GarColossus to be too difficult in relation to the other bosses, making it a hard road block before you can access the rest of the game.
The lethality level for bosses ranked from most to least dangerous:
- Mist Fog
- Stone golem
- Dragon
- Crystal
- Scorpion
- Octopus
- Guardian
- Bionic Flyer
- Demon
For being the first boss to encounter he is the second most difficult to take on, as 90% of attacks are useless, and his melee damage is insane, giving he has a chance for doublehit. Double Hit paired with fast AS makes every 2 attacks have a chance for a full hp kill, which means premptively hammering your space is a prerequesite.
So the tankines of the stone golem boss has nothing to do with his physical stats, but with his shield, which might have a secret trick to work around ?
-
10 hours ago, dimitrius154 said:
unless you hit 'Reset to Default' ingame.
I get it, it doesnt apply until somebodies uses the ingame "Reset to Default" button, or has a fresh installation.
This is the logfile if you merge a complete EE2.1 build with an unedited EE2.2 content: logfile.txt
-
Flix, could you look into the following problem.
EE2.2, SS, C: The Fog Boss Monster has an ultra hard hitting attack, which appears to be DOT, which one shots even the sturdiest builds.
L91, 11k hp, Ice Mitigiation 15% - 20% ?, 3934 Ice Armour (3x legendary ice reliqs) and the Boss still seems to apply 4000 dmg every 0.5 seconds over the course of 2.5 seconds. Which equals to 200% of the chars total hp.
Now I dont really want to complain about the difficulty on a Challenge run, but even though I have a ranged character it makes the boss fight even more lame than usual, not even talking about melee chars. So I would like to see a change which doesnt one shots every build in the game. A few example would be to spread out the damage from 2.5 seconds to the normal 5 or 7.5 seconds. Or maybe something else unexpected is going on.
To the relevant people, is there a way to make the hp bar update instant ?
-
14 hours ago, dimitrius154 said:
It's the intro volume, that's annoying, isn't it?
Eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeh .. DUH ?!
8 hours ago, dimitrius154 said:Hmm, by the way, I think, I understand, why the devs chose to utilize the .dds image format, despite the fact, that .tga works as well. It's about CPU use optimization. dds files can have in-built mipmaps, .tga's can't.
You lost me there.
14 hours ago, dimitrius154 said:That's because the keys in optionsDefault are processed in a way, different from other parameters.
Give me a rundown of the process: If I change teleport to F9 where is it getting saved ?
Also are multiposts allowed now ?
-
-
12 hours ago, Flix said:
Negative. It's not showing any editing timestamp on it.
Ok, so .. I assume a lot of ? in a row equal :). I assume thats autocorrect, and is made to save server space ? Im crying, and a laughing crazily a bit.
3 points
- With finishing the scripts folder I fail to see additional text files to write a modmerge system for. If you have any text files which still require some attention than please wishlist them now.
-
relations.txt is still unaccounted for because of this issue:
http://darkmatters.org/forums/index.php?/topic/23827-s2gcp16ee21ssc-esp-the-beginning-and-the-modmerging-system/&do=findComment&comment=7014812
Please take another look at the issue and suggest a solution. -
soundcluster.txt is still unaccounted for because of this issue:
http://darkmatters.org/forums/index.php?/topic/23827-s2gcp16ee21ssc-esp-the-beginning-and-the-modmerging-system/&do=findComment&comment=7014812
Please take another look at this issue and suggest a solution.
12 hours ago, dimitrius154 said:Do you mean the Ascaron logo cutscene? You could. Remove:
Phew. It .. works, and is nice. I suggest to implement this as for everybody else too. Or just wait until I release it as a standalone mod.
13 hours ago, Flix said:Despite this, optionsDefault.txt can be edited to force changes out at the mod-level instead of relying on each individual user to hunt down and make edits to a file in their AppData folder.
Does it force change the options.txt permanently with every start ? Or is it a temporary change for one session ? Im kinda confused because if optionsDefault.txt would be working nobody would be able to change keys anyway ?
Since autocorrect altered my original question, I still have no clue about roadmap.txt. Competent insight is welcome.
Ill promise I will merge this post with the one above as soon as I get to it.
Have a good start of the week :).
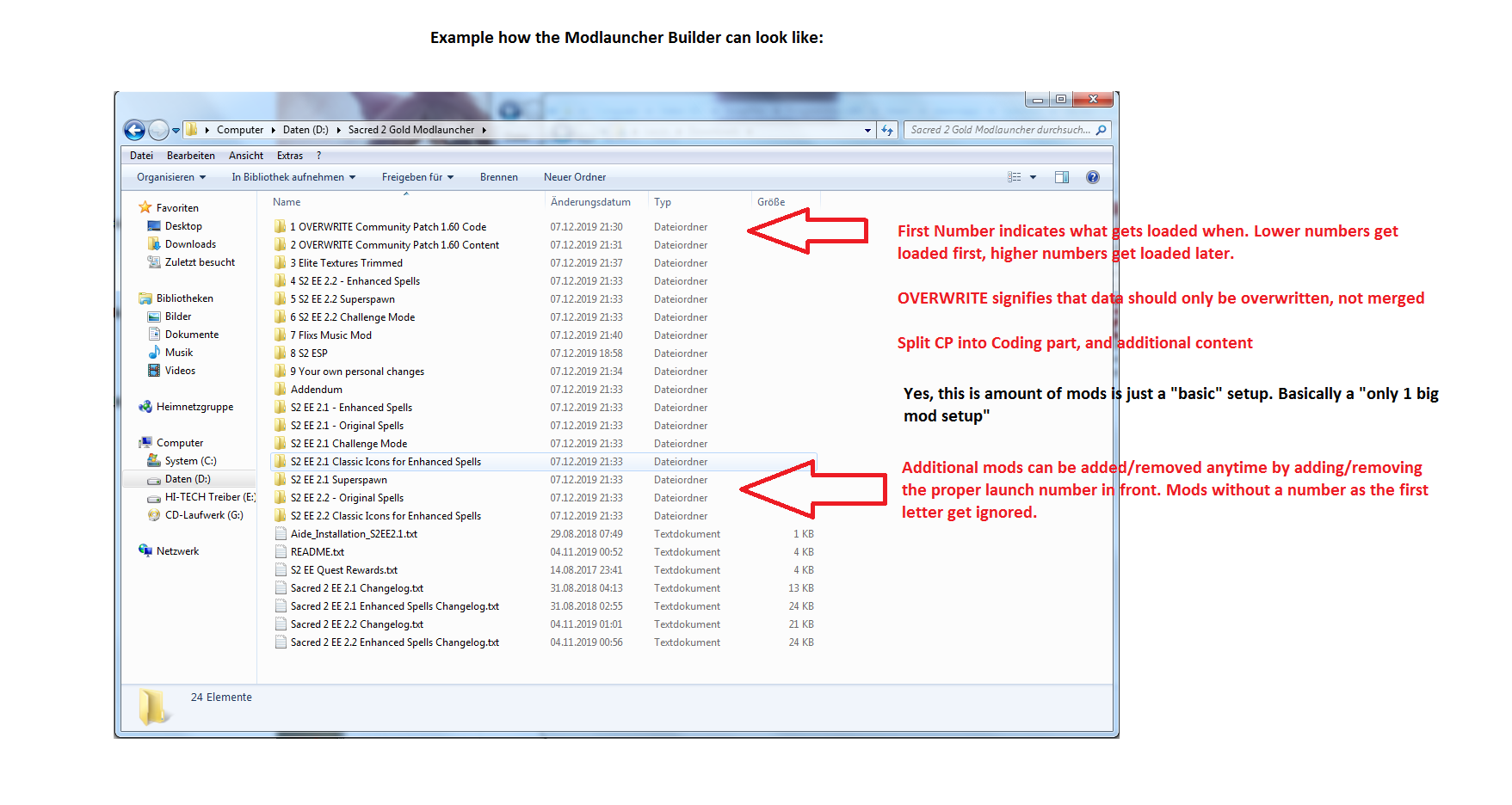
Modmerge Launcher [1.02]
in Sacred 2 Modding
Posted · Edited by Charon117
This is the Modlauncher and Modmerge Software
https://drive.google.com/open?id=1pIqHTeZGWu6RmlL5-cZJ8F1AcDG8ga40
Translate into mege link later on reminder.
[Problem]: The main problem with modding content is that it usually gets distributed as whole files, which means every mod content contains changes which are not necessarily necessary for the mod, but nevertheless have to get added in order to make a working file. If you want to release a mod that only changes the Critical Hit Factor you will have to include a hundred other changes, which basically reset any other changes in the same file to zero. The solution to this is to manually go into your files, and make all changes per hand, which is error prone, labor intensive and excludes less competent people.
[Problem]: The consequence of the first problem is that since mod content gets distributed as whole files mod content is highly sensitive to version changes for the base game, or any other modding content. If you have a mod that changes 2.43 base game skins than 2.44 might completely and irreversibly break your mod, and make it unuseable. The same goes if you use more than 1 mod at the same time. Any and every time a mod changes it can potentially risk breaking compabilitiy with any other mod out there. The adapted solution to this is to not have too many active mods at the same time, and dont use mods which change the same files, or even better, only use 1 big mod.
[Consequence]: Whether its Elder Scrolls, Fallout, or any other big or small game out there, the consequences are usually the same, modding content decays very quickly. Due to the high sensibility of version compability any time the base game or the modding scene makes a major step it leaves behind all other content, which needs a high grade of maintenance to stay up to date. Usually people dont do that amount of work, and as a consequence people usually concentrate on one big collaborated project, where the chance for longer maintenance is higher than small, unsupported mods somebody just made once and never plans to update it.
[Solution]: The solution to this is the Modmerge Software. The Modmerge Software allows mods to be saved as ideas, only containing the necessary data the mod wants to change or add. Problem number 1 gets solved because a mod does no longer contain changes it doesnt want to make. Problem number 2 gets dispelled because of the same reason, and because it minimises the amount of manintenance you have to make to keep it up to date.
The most fundamental idea of the Modmerge Software is that it interprets data as data, but also as a set of instrunctions to be applied to another build. Therefore modmerging content can be created in exactly the same way as normal mod content. The only thing you have to know as a mod author is the base games data structure, which you would have to know anyway. If the game understands the format, the Modmerge System will understand the format, with minor limitations regarding changing data structure.
The Modmerge Software takes mod content in exactly the same way and structure as the base game. It then
The zip contains
The Modmerge Software can be added to every mod, or even more easily just pointed towards the main page where people can download it. It should work with every existing mod, but it wouldnt do anything differently than copying over the whole file, in effect. I hope mod content which uses a dedicated Modmerge structure will get created, to take advantage of the system. I suggest tagging such content as [MSC] ModmergeSystemCompatible.
Most credit has to be given to @Flix and @dimitrius154 for supporting this project, as without their knowledge no modmerge rules could have been written. Props to them ! And ofcourse to Darkmatter, to host gaming and mod content alike so that people who like Sacred have a place to collaborativelly share their ideas and work in a cozy place. Props to the folks who keep Darkmatter alive !